Cloud-Native Disaster Recovery: Rethinking Resilience Beyond Backups


Traditional disaster recovery (DR) strategies, such as tape backups, cold storage and manual failovers, don’t fit cloud-native environments. Today’s cloud systems are distributed, dynamic, and constantly changing. Resilience now depends on architecture, automation, and speed.
This briefing reframes disaster recovery for modern cloud-native teams. It outlines why legacy approaches fall short and how to build a recovery model that prioritises speed, automation, and fault tolerance.
Why Traditional DR Doesn’t Work in the Cloud
Cloud-native systems operate on fundamentally different principles from traditional IT. Static backup routines, slow manual procedures, and single-region dependency leave organisations exposed.
1. Data Changes Constantly
Cloud workloads shift in real time. A snapshot taken hours ago may already be outdated. Fixed backup schedules struggle to keep pace with autoscaling, short-lived containers, and frequent deployments.
2. Manual Recovery Slows You Down
Legacy DR often depends on orchestrated scripts, manual approvals, or rebuilding environments by hand. In a cloud-native setup, infrastructure should be disposable and reproducible.
3. Backup ≠ Availability
Backups are necessary, but insufficient. If it takes hours to restore from them, your Recovery Time Objective (RTO) may already be breached.
4. Single Points of Recovery
Storing backups in the same region, or tying them to production IAM roles, creates risk. A regional outage or compromise can take out both production and your safety net.
What Cloud-Native Resilience Looks Like
Instead of reacting to failure, cloud-native recovery strategies assume failure and design for rapid restoration.
Infrastructure as Code for Fast Recovery
- Use tools like Terraform or Pulumi to redeploy infrastructure quickly and consistently.
- Store configurations in versioned, immutable repositories to enable clean rebuilds.
Immutable, Versioned Snapshot
- sSchedule automated snapshots of block storage, databases, and configuration states.
- Store snapshots in cross-region or isolated accounts to reduce risk during regional failures.
Multi-Region and Multi-Zone Redundancy
- Deploy critical services across multiple availability zones or regions.
- Use health-aware DNS or global load balancers to route around outages.
Automated Failover Workflows
- Configure routing policies with tools like AWS Route 53, Azure Traffic Manager, or GCP Load Balancing.
- Trigger failover events based on latency thresholds, health check failures, or business-defined signals.
Application-Level Resilience
- Prioritise stateless design for services to simplify rehydration.
- Use managed services with built-in DR features where available (e.g., DynamoDB global tables, GCS dual-region buckets).
Note: Some cloud-native managed services, such as Amazon RDS or BigQuery, may still require manual intervention during DR. Ensure procedures for these are clearly documented and included in DR tests.
Key Questions to Pressure-Test Your Strategy
Before the next failure…not after…ask your team:
- Can we rebuild our production environment from code alone?
- Are our DR plans documented, versioned, and tested regularly?
- What are our RTO (Recovery Time Objective) and RPO (Recovery Point Objective), and are they still achievable?
- Which workloads are tied to a single region or availability zone?
- What happens if IAM, DNS, or secrets management is compromised?
Modern DR Checklist
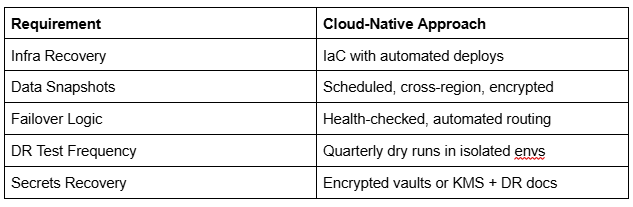
Final Thoughts
Cloud-native disaster recovery isn’t about perfect prevention, it’s about rapid, reliable recovery. Backups are table stakes. The real goal is reducing downtime, controlling impact, and restoring trust quickly.
One engineering team, for example, cut recovery time from three hours to under 15 minutes by combining Terraform-based infrastructure, isolated secrets workflows, and automated cross-region replication. Their quarterly DR tests now run as part of their sprint cadence and are tracked as an engineering KPI, not an afterthought.
A modern DR strategy also strengthens your compliance posture. It supports regulatory expectations around availability and continuity, including APRA CPS 234, ISO 27001 Annex A.17, and SOC 2 trust principles.
If your infrastructure can scale on demand, it should recover on demand, too. The shift isn’t from backup to resilience, it’s from manual to automatic, from fragile to fault-tolerant.
Related Resources



Find your Tribe
Membership is by approval only. We'll review your LinkedIn to make sure the Tribe stays community focused, relevant and genuinely useful.
To join, you’ll need to meet these criteria:
> You are not a vendor, consultant, recruiter or salesperson
> You’re a practitioner inside a business (no consultancies)
> You’re based in Australia or New Zealand